ALSO READ:
Things you must keep in mind before you upgrade or downgrade kernel in Linux
What is kdump?
kdump is a reliable kernel crash-dumping mechanism that utilizes the kexec software. The crash dumps are captured from the context of a freshly booted kernel; not from the context of the crashed kernel. Kdump uses kexec to boot into a second kernel whenever the system crashes. This second kernel, often called a capture kernel, boots with very little memory and captures the dump image.
Using kdump allows booting the capture kernel without going through BIOS hence the contents of the first kernel's memory are preserved, which is essentially the kernel crash dump.
Memory requirements
In order for kdump to be able to capture a kernel crash dump and save it for further analysis, a part of the system memory has to be permanently reserved for the capture kernel. When reserved, this part of the system memory is not available to main kernel.
The memory requirements vary based on certain system parameters. One of the major factors is the system’s hardware architecture. To find out the exact name of the machine architecture (such as x86_64) and print it to standard output, type the following command at a shell prompt:
# uname -m
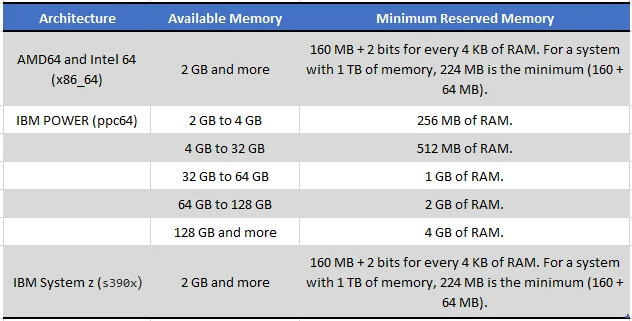
Another factor which influences the amount of memory to be reserved is the total amount of installed system memory. For example, on the x86_64 architecture, the amount of reserved memory is 160 MB + 2 bits for every 4 KB of RAM. On a system with 1 TB of total physical memory installed, this means 224 MB (160 MB + 64 MB).
Minimum Amount of Reserved Memory Required for kdump
Installing kdump
In order use the kdump service on your system, make sure you have the kexec-tools package installed.
To do so, type the following at a shell prompt as root:
# yum install kexec-tools
On IBM Power (ppc64) and IBM System z (s390x), the capture kernel is provided in a separate package called kernel-kdump which must be installed for kdump to function:
# yum install kernel-kdump
Adding Boot Parameters
The "crashkernel=" option can be defined in multiple ways.
- The auto value enables automatic configuration of reserved memory based on the total amount of memory in the system. Starting with RHEL7 kernels crashkernel=auto should usually be used. The kernel will automatically reserve an appropriate amount of memory for the kdump kernel.
NOTE: RHEL7 with crashkernel=auto will only reserve memory on systems with 2GB or more physical memory. If the system has less than 2GB of memory the memory must be reserved by explicitly requesting the reservation size, for example: crashkernel=128M.
- Some systems require to reserve memory with a certain fixed offset. If the offset is set, the reserved memory begins there. To offset the reserved memory, use the following syntax:
crashkernel=128M@16M
The example above means that kdump reserves 128 MB of memory starting at 16 MB (physical address 0x01000000). If the offset parameter is set to 0 or omitted entirely, kdump offsets the reserved memory automatically
Sample GRUB2 config file (/etc/sysconfig/grub)
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="novga console=ttyS0,115200 panic=1 numa=off elevator=cfq rd.md.uuid=3b1e2dc9:8f31253e:a3a9cb3f:2c9cd9d1 rd.lvm.lv=os/root rd.md.uuid=dbf7f100:c0850807:9423a785:1a3f0acd rd.md.uuid=31eb0dce:3cc298b6:8d64f1d1:e3db25b2 rhgb quiet crashkernel=auto"
GRUB_DISABLE_RECOVERY="true"
After modifying /etc/sysconfig/grub, regenerate the GRUB2 configuration using the edited default file. If your system uses BIOS firmware, execute the following command:
# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-3.10.0-862.6.3.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-862.6.3.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-744622670ad74ca599b5c9c5734c1c81
Found initrd image: /boot/initramfs-0-rescue-744622670ad74ca599b5c9c5734c1c81.img
done
NOTE: After adding the crashkernel parameter the system must be rebooted for the crashkernel memory to be reserved for use by kdump.
Where to find generated vmcores?
When the hypervisor comes back up, the vmcore can be found by default under /var/crash/:
[root@host ~]# egrep '^path' /etc/kdump.conf
path /var/crash
IMPORTANT NOTE: Make sure the free diskspace of the partition which you have specified for storing the vmcore is at least larger than the whole physical memory on the system. In case your physical memory is 131GB, keep the diskspace / size of the location atleast more than 131GB which you use in kdump.conf
Configuring the core collector
To reduce the size of the vmcore dump file, kdump allows you to specify an external application (a core collector) to compress the data, and optionally leave out all irrelevant information. Currently, the only fully supported core collector is makedumpfile.
To enable the dump file compression, add the -c parameter. For example:
core_collector makedumpfile -c
To remove certain pages from the dump, add the -d value parameter, where value is a sum of values of pages you want to omit.
For example, to remove both zero and free pages, use the following:
core_collector makedumpfile -d 17 -c
Supported Filtering Levels

Enabling the service
To start the kdump daemon at boot time, type the following at a shell prompt as root:
# systemctl enable kdump.service
This enables the service for multi-user.target. Similarly, typing systemctl stop kdump disables it. To start the service in the current session, use the following command as root:
# systemctl start kdump.service
Testing the kdump configuration
To test the configuration, reboot the system with kdump enabled, and make sure that the service is running:
# systemctl is-active kdump
active
Then type the following commands at a shell prompt:
echo 1 > /proc/sys/kernel/sysrq
echo c > /proc/sysrq-trigger
This forces the Linux kernel to crash, and the address-YYYY-MM-DD-HH:MM:SS/vmcore file is copied to the location you have selected in the configuration (that is, to /var/crash/ by default).
# tree /var/crash/
/var/crash/
├── 127.0.0.1-2018-08-20-13:12:35
│ └── vmcore
│ └── vmcore-dmesg.txt
└── lost+found
Analysing hung task
We must use "hung_task_panic" which controls the kernel's behavior when a hung task is detected.
This file shows up if CONFIG_DETECT_HUNG_TASK is enabled.
0: continue operation. This is the default behavior.
1: panic immediately
For temporary changes:
# echo 1 > /proc/sys/kernel/hung_task_panic
For permanent changes
# echo 'kernel.hung_task_panic=1' >> /etc/sysctl.d/99-sysctl.conf
# sysctl -p
With this whenever a blocking process as seen is seen, a kernel panic will happen and core dump will be generated which can be abalysed further to debug the issue.
kernel: INFO: task taskMonitor:6223 blocked for more than 120 seconds.
kernel: INFO: task top:7355 blocked for more than 120 seconds.
I hope the article was useful.